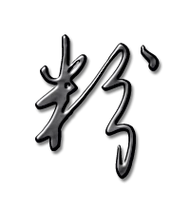首页
小红书点赞
小红书粉丝
小红书刷粉丝买粉丝刷点赞小眼睛自助下单平台
首页
jfgjhgf
如何整理笔记:分类和聚类
红薯号
•
2024年12月8日 下午6:53
•
jfgjhgf